Most IT development done nowadays involves development of some sort of message processing system (MPS). These MPSes can be simple and based on nothing more than message passing in the object oriented sense of the word, or they can be convoluted and even esoteric systems (ranging from SOA components included in an ESB to JMS-driven MDBs and so on). In all cases they are based around the paradigm of messaging — passing of messages from a client to an MPS and often having the MPS send a second message back in response. The MPS responds to an incoming message by doing some form of work based on the message’s contents, possibly delegating part of that work to third systems (in which case the MPS takes on an orchestrating role as well as a primary processing role). Almost any system currently being developed and maintained in the Enterprise software development sphere fits the paradigm; the business layer in the three-tier JEE model is already an example.
In this article I want to discuss some best practices when designing and developing these systems:
- Separating business logic from publishing frameworks
- Mocking backends
- Logging messages so that they will be reusable in testing and problem analysis
Probably none of these best practices will bowl you over. In fact, you’re probably underwhelmed by the list so far. So why am I going to waste an entire blog talking about these boring basics of development? Because, for some reason, most projects still seem to overlook any or all of the points mentioned above…..
Separate business logic from publishing framework
A typical MPS is based on at least one framework to handle the details of the message transport layer. Examples of such frameworks abound; the Java development platform alone has many, ranging from the (Server)Socket through the Servlet to JAX-WS and JAX-RS implementations, plus the non-standardized ones like Struts, SpringMVC, Spring WebFlow, SpringWS, JXTA, Apache ActiveMQ, etc. All these frameworks have in common that they provide an infrastructure for the application up to a point and then a way for you to insert your own business code at that point. Take, for example, Servlets (I’m assuming most people will be familiar with those): the Servlet specification details how these server extenstions fit into existing servers, how the container is supposed to handle threading and lifecycle management plus context management as well and then it defines the primordial Servlet interface. Developers can implement this interface as a way of hooking their own code into the defined infrastructure. Essentially, the following structure is used:
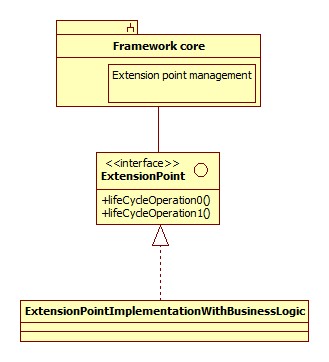
Best practice: Don’t ever hook your MPS business logic into the framework using the provided extension point directly. Instead, put your business logic behind a simple object service layer; then create a framework extension point that delegates to this service layer.
Best practice diagram:
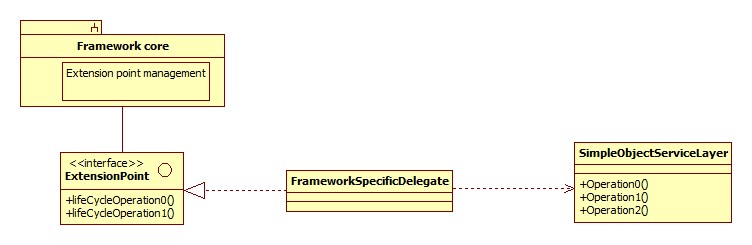
Reason: If you use the extension point directly, you run a huge risk of hard-linking your MPS implementation to the framework-du-jour, making it difficult to publish the same business service in a different way. As a side-effect, you can also end up making it very difficult to test your business logic.
Examples: Let’s stick with the servlet example. So here you are, having to implement a business service for publishing as a web application. So you write a servlet, override the doGet() method and implement your service. You have now:
- Made it impossible to publish that same service as a web service using (say) JAX-WS, because you cannot publish a servlet in any other meaningful way.
- Made it very difficult to unit test your service (you’ll probably need a servlet container running to test, which is tedious at best).
- Made it difficult to set up a feedback loop of test cases from the test team (or from live), since you cannot easily capture a request from live in a transferrable or persistable object that you can reload and run through your implementation at will (this is an extension of the previous point).
Compare this to the shape you would have been in if you had implemented a standalone service in your domain model and delegated to that from a servlet:
- You could have republished the service in any framework by creating a delegate for each framework.
- You could have run the whole MPS code through from a repeatable unit test.
- Since your service requests would necessarily have been simple objects and not framework-specific objects, you could have captured and persisted problematic request in testing (or on live) for debugging and then made them part of the test suite.
Mock your backends
Unless your MPS has very simple responsibilities, it is likely that it will require help from some other MPS to complete its task (even a persistent datastore counts as a separate backend in this example). The dependency on backend systems means that your own MPS will consist of more than just business logic; it will include code that allows it to integrate with the backend system, to speak its protocol and connect to it using some medium.
Best practice: Make sure you hide your backend system from your main MPS implementation using an interface and that you have a mock implementation of the backend that implements this interface.
Reason: Testability. Having a mock for each backend allows you to test your system in isolation. It also allows you to create repeatable tests even for non-idempotent backend operations.
Mocking solutions: There are all sorts of mocking solutions available, ranging from the really simple (the fixed answer to any message) to the very complex (answers based on message contents using scripting and so on). There are lots of tools available nowadays to help you out, for any kind of system — ranging from EasyMock and jMock to SoapUI (for web service mocking) and all sorts of other options. Ideally you should aim for a solution that gives you a good balance between versatility (i.e. not being stuck with one, fixed answer) and ease-of-use (it shouldn’t be difficult to set up and use the mock). Also remember you will need mock capabilites at all levels of your architecture — so if you are developing a component that orchestrates two others that each use third-party services, you will need mocking for three components.
Examples: On my current project, we have a lot of dependencies on backend systems (ranging from databases to thrid-party service providers). Unfortunately, a number of third-party test systems are not very reliable. If they are down, testing cannot proceed. And even if they are up, test data creation takes a long time. Which is bad, because most tests mutate the test data in a way that cannot be easily reversed, which means most tests (even failing ones) are one-shot deals. So if your test fails, at best you have to wait a long time for another attempt.
If there were proper mocks for all our backend dependencies, we could have a whole stack of scenarios in replayable test data. We could test if the test systems were down, we could test as often as we liked until we got it right.
Log messages for (re)use in testing and problem analysis
While your MPS is under development, you will probably use mocked test data for your unit and integration testing. The test phase (where the test team starts using your MPS) and the real test phase (when your MPS has gone live) however, will always yield situations and messages that you hadn’t quite counted on. During the testing phase, if something breaks, you can always refer to the test script used by the testers to approximate what they were doing — but nothing is as telling or useful as debugging with the actual message they fed into the system (or message chain, as the case may be). On live, you don’t have a script to refer to; the only hope you have for solving a live issue is to capture the message that set off problems in the system.
Best practice: From the very start of development, incorporate mechanisms into your MPS that can log all incoming and outgoing message traffic in a format that you can easily feed back into te system.
Reason: Repeatable problem analysis and testing. If you can capture (problematic) requests and exactly reconsitute the messages that entered the system, you can debug exact problems — and build a repeatable test suite that prevents the problems from reoccurring.
Logging strategy: The trick to logging messages for problem analysis and repeatable testing, is to make sure that you don’t just log. Rather, you must log in a format that you can easily and automatically regenerate exact messages from. In some cases that is very easy and it seems the obvious thing to do (like storing XML representations of XML documents in a web service implementation). However, the same rule applies in cases where it may not be as easy to do (like in the case of your message consisting of an object tree rather than a structured XML document).
It is important in these cases to resist the temptation to log a number or printlines to describe the object and think this is well enough (e.g. attribute A = “Bla”; attibute B = “Boo”; attribute C = 5; etc.). Such naive representations cannot generally be reconstituted easily into actual messages that can be fed back into the system and the value of these representations to the testing of your system will be low. Although it may require upfront effort, it is always a vastly better idea to investigate or even build some tooling that will allow you to persist and reconstitute messages automatically.
Example: A reasonably useful (although largely obscure) tool set for persisting and reconstituting JavaBeans exists within the JDK itself (since version 1.4). It is a toolset formed by the java.beans.Encoder and java.beans.Decoder interfaces, which specify classes that can encode and decode graphs of objects that follow the JavaBeans Specification. Encoder implementations transform JavaBeans into a series of statements and expressions that describe how to create a JavaBean instance with a state such that it is equivalent to the original bean — this series may then be persisted in any useful fashion and replayed any number of times by a Decoder implementation. The JDK also includes an example implementation (the java.beans.XMLEncoder and java.beans.XMLDecoder) that encode a JavaBean graph into an XML document describing how the graph was built. This is a useful toolset and even though support for indexed properties is very weak, it is quite adequate for the simple JavaBeans in common use today.
Conclusion
In this article I have attempted to review some very simple best practices in developing Message Processing Systems that somehow keep getting missed by an awful lot of projects. These best practices make your life as an MPS developer much easier (not to mention the life of the poor guy who has to maintain the system after you’ve moved on) and they are usually relatively easy to put into practice. Now if only we all would…..