One of my current projects is responsible for delivering a library of functions that are used by several applications being built and maintained at our customer. One of those functions in particular is quite central to the operation of all the applications that use out library and is responsible for collecting, transforming and combining data from many different sources (essentially it is an orchestrating function). This function has a classical codebase, in the sense that the codebase started out being much smaller than it is now and with fewer tasks but has since grown. The library function is being developed continuously and will be expected to meet more and more requirements as more and more data must be collected and correlated. The problem, as you can imagine, is that the codebase is becoming unmanageable as more and more code goes into it. So we are faced with the question: how can we refactor the existing codebase to improve manageability?
As mentioned before the function in question is essentially an orchestrator, collecting data from several locations and combining these different data into one package. The collection of data is not random, however: some requests depend on the results of others, creating a natural partitioning of the function’s code into tasks with an internal ordering. Of course, this sounds like a classical orchestration setup and the first suggestion might be to use an orchestration tool like a BPEL engine. However, integrating a BPEL engine into the library seems like overkill given the current size and complexity of the function (and doesn’t fit well with the rest of the library). So instead my project is going to attempt an intermediate solution between the current pile-of-code architecture and a full orchestration tool: the Life Cycle Pattern.
The setup
Now, I have to admit to a little marketing here: there is (to the best of my knowledge) no official pattern called the “Life Cycle Pattern”. What I am talking about in fact is, in fact, a refactoring of our current pile-of-code collection of tasks (collecting data, transforming data, combining data and similar) into a collection of separate task objects, each of which is associated with one (or more) explicily identified steps within the overall library function.
Let me start from the other end to explain. I assume most people reading this article have at least heard of the maven build management tool. This tool (starting with version 2.0) divides the build process into a number of distinct steps or stages (clean, generate-sources, compile, test, package, deploy, etc.) which are together known as the build life cycle. A run of the maven executable runs through each of the stages in order. At each stage the executable delegates to zero or more modules (in the case of maven they’re called mojos) each of which attempts to carry out a task (in maven-speak, attempts to achieve a goal). Which module is associated with which stage is determined by configuration.
Patterns
From a design pattern point of view, the “life cycle pattern” is actually a combination of two patterns: the Mediator pattern and the Command pattern. The first of these is a pattern that deals with having a central controller that delegates to a number of objects (each with their own responsibilities within the system) and controls their execution order to create a process. The second is a pattern that deals with turning system tasks into objects. The pattern actually exists to turn tasks into first-class citizens of a system so that they can be manipulated (e.g. reversed, as in an “Undo” functionality). In our case however we just want to make tasks manageable to associate them with steps. The structure we are aiming for is the following:
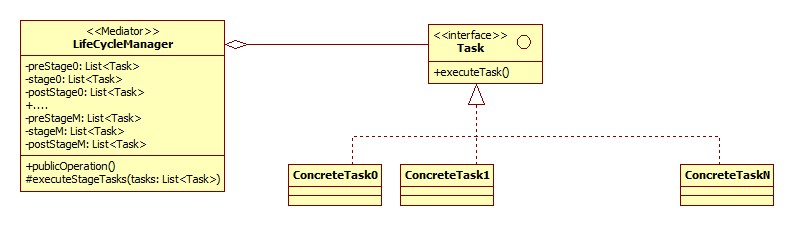
In this design the LifeCycleManager is the class that is responsible for controlling the entire process with its different steps (in our case: the class that provides the library function). The operation that is called to kick of a process instance is referred to as the publicOperation() in the diagram above (in general this method will probably have one or more parameters). In the design above this method is the one that knows about the exact order in which the life cycle stages should be executed. As you can see, each stage is associated (in this design) with a list of Task objects. The publicOperation() method passes each of these lists to the executeStageTasks() method in the correct order. This method iterates over the Tasks in the list it is passed and calls executeTask() on each Task. The execution of this setup is illustrated in the following sequence diagram:
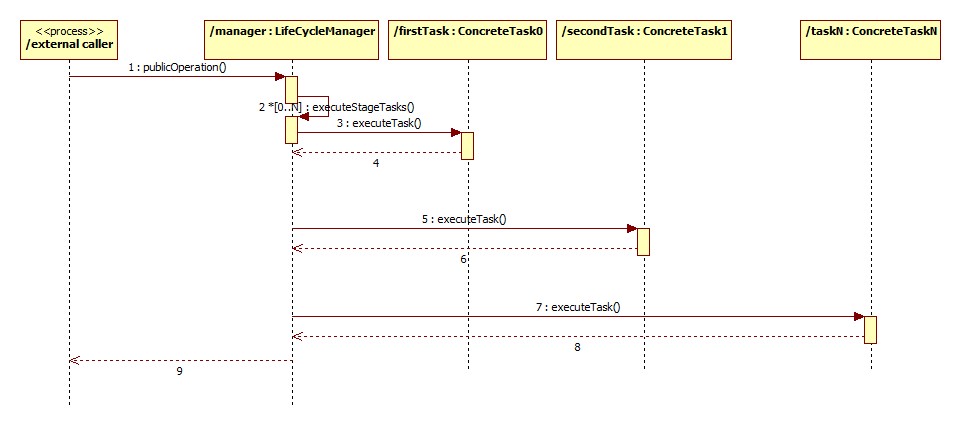
Code example
In the following section I will include a small code example of this “pattern”. The example is a Springified one, which means that the association of tasks to stages is done by dependency injection (in this case of the lists of Task objects into the LifeCycleManager). As illustrated in the design above, Task is just an interface that defines the Task hierarchy.
package nl.bentels.test; /** * This interface defines the Task type, the type of any task that can be * executed as part of a life cycle. * * @author ben.tels */ public interface Task { /** * Method that executes a task. */ void executeTask(); }The
LifeCycleManageris also unsurprising:package nl.bentels.test; import java.util.List; /** * This class is responsible for managing and executing the life cycle of * whatever it is that the life cycle blongs to. * * @author ben.tels */ public class LifeCycleManager { /** Preparation tasks for stage 0. */ private List preStage0; /** Tasks for stage 0. */ private List stage0; /** Postprocessing tasks for stage 0. */ private List postStage0; /** * The operation that can be invoked by an external entity. */ public void publicOperation() { executeStageTasks(preStage0); executeStageTasks(stage0); executeStageTasks(postStage0); } /** * Iterate over the tasks for a life cycle stage and execute them. * * @param tasks The tasks. */ void executeStageTasks(final List tasks) { for (Task task : tasks) { task.executeTask(); } } /** * @param preStage0 the preStage0 to set */ public void setPreStage0(final List preStage0) { this.preStage0 = preStage0; } /** * @param stage0 the stage0 to set */ public void setStage0(final List stage0) { this.stage0 = stage0; } /** * @param postStage0 the postStage0 to set */ public void setPostStage0(final List postStage0) { this.postStage0 = postStage0; } }In order to make a full example, I’ll provide an example task implementation. This one does nothing but print a number:
/** * */ package nl.bentels.test; /** * This class is an example task. * * @author ben.tels */ public class ExampleTask implements Task { /** Number of the task. */ private final int taskNumber; /** * @param taskNumber */ public ExampleTask(final int taskNumber) { this.taskNumber = taskNumber; } /** * {@inheritDoc} */ @Override public void executeTask() { System.out.println(taskNumber); } }Finally, the Spring configuration:
< ?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="lifeCycleManager" class="nl.bentels.test.LifeCycleManager"> <property name="preStage0"> <list> <ref local="taskZero" /> <ref local="taskOne" /> <ref local="taskTwo" /> </list> </property> <property name="stage0"> <list> <ref local="taskZero" /> <ref local="taskOne" /> <ref local="taskOne" /> <ref local="taskOne" /> <ref local="taskTwo" /> <ref local="taskOne" /> <ref local="taskTwo" /> <ref local="taskZero" /> <ref local="taskOne" /> </list> </property> <property name="postStage0"> <list> <ref local="taskZero" /> <ref local="taskZero" /> <ref local="taskTwo" /> </list> </property> </bean> <bean id="taskZero" class="nl.bentels.test.ExampleTask"> <constructor -arg value="0" /> </bean> <bean id="taskOne" class="nl.bentels.test.ExampleTask"> <constructor -arg value="1" /> </bean> <bean id="taskTwo" class="nl.bentels.test.ExampleTask"> <constructor -arg value="2" /> </bean> </beans>Moving on….
Like I said, this mechanism is not in place yet; the project is only about to start working on it. This means that there are still considerations open, such as how to arrange communication (or state sharing) between the tasks of the process. Of course I will report on the outcome (once it is known) in a sequel to this article…..
The Life Cycle Pattern