This year, 2009, we celebrate the 50th anniversary of a landmark moment for (Dutch) computing science: it is 50 years ago this year that Edsger Wybe Dijkstra, The Netherlands’ most famous computing scientist, published his Shortest Path Algorithm in Numerische Mathematik, the German journal of numerical mathematics.
The shortest path algorithm is a solution to a problem from graph mathematics. A graph is a mathematical construct consisting of vertices (or nodes) connected by edges (or sides). Each path has a value (a length, a cost, etc.). The object of the problem is to find the shortes path through the graph from one point to a certain other point. And just in case that sounds like abstract mathematical nonsense that nobody will ever have use for: this problem and its solutions have been applied to network routing, traffic pattern regulation and worldwide distribution of goods. For those of you who drive cars: next time you get in you car, take a look at your satnav — then say “thank you Edsger”.
Dijkstra’s algorithm is not the first solution to this problem. However, his solution differed from the solutions presented before in that it is simple and straightforward (most textbooks and professors covering the subject even remark that it is strange that nobody came up with this easy solution sooner). It is also one of the first solutions that was designed with implementation on a computer in mind, so it is optimal with respect to running time and storage need. This in turn undoubtedly explains its pervasiveness throughout computing even (or only?) 50 years after its invention. It’s also why Dijkstra is most famous internationlly for this algorithm; even to the point of being insulting, because it is really one of the least impressive results of his career, which literally lifted computing science from trial-and-error tinkering to a science.
Dijkstra’s career focussed mostly on developing the science of computing science, by developing techniques for constructing provably correct solutions to problems by constructing the solutions hand in hand with the proof of correctness. Dijkstra was a great believer in computing science’s mathematical roots because exactly those roots yield the properties that computing science so desperately needs: correctness, accuracy and elegance. One of Dijkstra’s axioms in fact is that Beauty is our Business. So in that spirit (and, I hope, in Dijkstra’s spirit as well) I would like to present this birthday salute to Dijkstra’s algorithm – and to the man himself as well: a construction of Dijkstra’s Algorithm.
Some basics
First, let’s cover some basics from graph theory.
First of all, a graph G consists of two sets V(G) and E(G).
- The set V(G) is the set of vertices (or nodes) of G and is simply a set of names. For example, V(G) = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10} defines a vertex set for a graph consisting of eleven nodes, using a natural number to label each vertex.
- The set E(G) is the set of edges (or sides) of G and consists of pairs of vertices from V(G); the interpretation is that if a pair of vertices is in the set E(G), then those vertices are connected by an edge in the graph G. Since we allow for incomplete graphs (graphs in which not every pair of vertices is connected), we formally define E(G) to be a subset of the set of all possible pairs of vertices: E(G) in V(G) × V(G).
For example, given the set V(G) above, we might have E(G) = { (0,1), (1,0), (0,2), (2,0), (0,3), (3,0), (1,5), (5,1), (1,6), (6,1), (2,5), (5,2), (3,4), (4,3), (4,7), (7,4), (4,8), (8,4), (5, 10), (10, 5), (6,9), (9,6), (7,8), (8,7), (8,9), (9,8), (8,10), (10,8)}.
At this point a small note is necessary on the difference between directed and undirected graphs, that is graphs of which the edges can only be traversed in one direction and graphs of which the edges can be traversed in both directions. This can make a difference in how the set E(G) is interpreted. For simplicity sake we will pretend in the formal definition that every edge is directed and that an undirected graph is one for which the following predicate holds:
forall v,w in V(G): (v,w) in E(G) => (w,v) in E(G)
That is, if an edge exist in the graph, then the edge in the reverse direction also exists in the graph. If we use these semantics the example of an edge set given above describes an undirected graph.
Of course a graph may also be depicted visually. If the graph is not too large, doing so might provide insight. The graph described in the examples above, for instance, might be depicted like this:
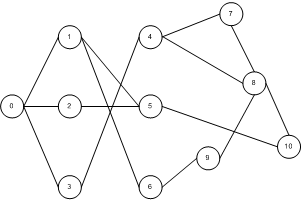
Note that in this example I’ve drawn the edges as single, undirected lines. A more correct alternative would have been to draw two edges with arrows for each line, one going in one direction and one in the opposite. However, this way of drawing is clearer.
As mentioned earlier each edge has a value which will be used to determine its “cost” of use. Formally we do this by introducing a weighting function, which is a function from the set of edges to the natural numbers or the positive real numbers: weight(G): E(G) –> R+. Note that it is important not to allow a negative weight; as we will see later, this breaks the algorithm. Also note that for undirected graphs we have an extra rule for the weighting function: forall v,w in E(G): weight((v,w)) = x => weight((w,v)) = x (i.e. in an undirected graph the weight of an edge and its “reverse” edge are the same).
As final part of the preliminaries, we have to formalize the concept of a path and the length of a path. Of course we all have an intuitive notion of what a path is: it’s a route you can follow over the edges of a graph to get from one vertex to another. More formally we will say
-
there is a simple path Ps(v,w) from vertex v to vertex w iff (v,w) in E(G)
-
there is a path P(v,w) from v to w iff there is a path from v to z and there is a simple path from z to w
Note that we will use the notation ++ to mean adding an edge to a path.
Given the definition above, the following definition of the length or cost C of a path won’t be very surprising. For a path P, the cost C(P) =
-
P = P(v,v) => C(P) = 0 (i.e. staying where you are is free)
-
P = Ps(v,w) => C(P) = weight((v,w))
-
P = P(v,z) ++ Ps(z,w) => C(P) = C(P(v,z)) + weight((z,w))
Some help
In order to help us out later on, we now introduce a helper thesis Th0:
Th0: Let P(v,w) be a path on graph G and Ps(w,z) be a simple path on G. Then C(P(v,w)) < = C(P(v,w) ++ Ps((w,z)).
Proof: C(P(v,w) ++ Ps(w,z)) = C(P(v,w)) + weight((w,z)). Due to the definition of the weighting function 0 <= weight< /strong> ((w,z)).
The shortest path algorithm
Given a graph and two vertices of that graph (one starting vertex and one end vertex), our goal is to find the shortest (the lowest cost) path between the starting and end vertices. For example, in the example graph above, we might want to find the shortest path between node 0 and node 10.
In general we will not be able to find the shortest path just by looking at the graph, that’s too difficult. But we might be able to come up with a way of constructing the shortest path one step at a time. This is the idea of the Shortest Path algorithm: building up the shortest path with small steps. Very small steps in fact: one edge at a time.
Let’s think a little about our problem. We have a set of vertices, two of which have a special meaning (start and end). We also have a set of edges (for simplicity sake we will assume the graph is connected, i.e. there is some way to get from any node to any other). And we have a weighting function, so we have costs for each edge in the graph.
After some thought on this problem, it occurs to us that we can also make a partition of the vertices into two separate sets: a “green” set of vertices of which we know the shortest path to the starting node, and an uncolored set containing all the other nodes. But do we know any such shortest paths? Yes: the shortest path from the starting vertex to itself has cost 0.
Here’s another thought: we know individual costs of each edge. That means that, in addition to our green set, we can create a “blue” set of vertices as well: a set of vertices not the in green set, but connected by a single edge to a vertex in the green set. Of the vertices in the blue set we know the length of a path to the starting node. It may not be the shortest path, but certainly a path. Having the blue set also has another consequence: for every node in the green set, we know something of each of its neighbors, each vertex to which it is directly connected. Specifically, each neighbor of a vertex in the green set is either in the green set or in the blue set.
So now we have three sets of vertices: the green set (of which we know the length of the shortest path to the starting node), the blue set (of which we know the length of a path to the starting node) and the rest (let’s call that the white set). So here’s a question: can we come up with rules for moving vertices from one set to another (preferably to the green set)?
Well, adding a node to the blue set is easy: pick a node from the green set. All of its neighbors can be added to the blue set.
But what about the green set? How do we pick a node from the blue set to add to the green set? That’s not so easy, because before we can move a vertex from the blue to the green set we must be able to guarantee that we know the length of the shortest path to the starting vertex. And we don’t.
The problem is that we don’t know enough about the blue set. We’ve been rather lax in how we’ve added vertices to the blue set — so far we’ve said that a vertex being in the blue set means it’s connected to a green vertex and that we know the length of a path from that node to the starting vertex. But we need more. And if we’re careful, we can actually know more: we can know the shortest path from the starting vertex to each blue vertex that we’ve seen so far.
For each green vertex, we know the shortest path from the starting vertex. Say that we’ve just determined the shortest path for a vertex V and have added it to the green set. Now let’s examine all the neighbors of V that are not in the green set. There are two possibilities for each neighbor Z:
- Z is in the white set. Then we can add Z to the blue set. The path P(starting vertext, V)++Ps(V,Z) is the shortest path to Z we’ve seen so far.
- Z is in the blue set. Then there are two possibilities:
-
- The path P(starting vertext, V)++Ps(V,Z) is shorter than the shortest path to Z we’ve seen so far. Then we’ve found a new shortest-path-so-far to Z.
- The path P(starting vertext, V)++Ps(V,Z) is not shorter than the shortest path to Z we’ve seen so far. Then we stick with the path we already had found.
If we use this process consistenly when adding vertices to the blue set, then we will always have a shortest-path-so-far associated with each blue vertex. And now we have a full solution in reach:
- Theorem Th1: The blue vertex with the shortest shortest-path-so-far can be moved to the green set.
After we’ve added a vertex to the green set and recalculated all the shortest-paths-so-far for the blue set, at least one of the blue vertices will be associated with the shortest of all the shortest-paths-so-far. That path to that vertext (say Z) is the shortest path from the starting vertex to Z. In this path Z is directly connected to green node V.Proof:
-
- The path P(starting vertext, V)++Ps(V,Z) is the shortest path from the starting node over all-green vertices and then directly to Z. We know this because we have examined all such paths while constructing the blue and green sets.
- There is no shorter path to Z over green and blue vertices. We know this because the path to Z we have now found is the shortest shortest-path-so-far and adding more edges will only result in a longer path (due to theorem Th.0).
- There is no shorter path to Z over white vertices either. Any path to Z over white vertices, by construction, must consist of a shotest-path-so-far to some blue vertex, plus a path over some white vertices. Theorem Th.0 tells us such a path must be longer than the shortest-path-so-far we have found to Z.
So now we have all the parts we have to come up with a working shortest path algorithm:
{* VG is the set of vertices, START is the starting vertex, END is the end vertex *}
set G := {START}, B := {}, W := VG \ {START};
node working := START;
START.length := 0;
START.prev := -;while not END in G –>
for node n in neighbors(working) and n not in G –>
if n in W –>
n.length := working.length + weight(working, n);
n.prev := working;
B, W := B union {n}, W \ {n}[] n in B and working.length + weight(working, n) < n.length –>
n.length := working.length + weight(working, n);
n.prev := working;fi
rof;
let node m = “the node with the minimum length in B”;
G, B := G union {m}, B \ {m}elihw
Note that in this implementation we save a “back reference” for each node as it is added to the blue/green set. This allows us to store the shortest paths and know the path as well as the length once the entire algorithm is done. The following animation demonstrates the process visually for our example graph for one possible weighting function:
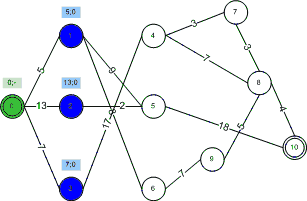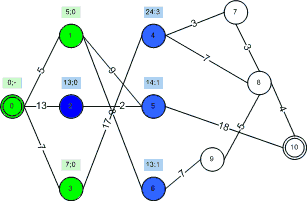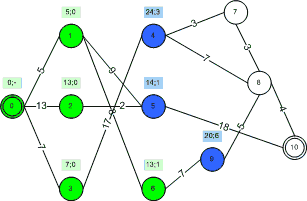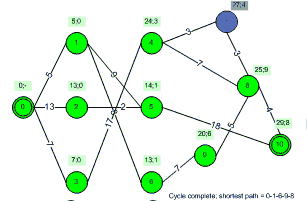
Some notes on the weighting function
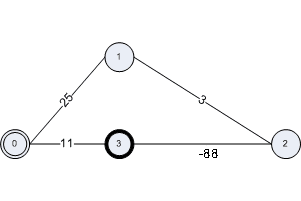
I mentioned earlier that it is important that no negative weights be used in the Shortest Path Algorithm. The reason for that can be seen in the reasoning for moving a node from the blue to the green set. If we are to assume that a path over the white nodes cannot be shorter than the shortest-path-so-far, we must really know that a path extended with an edge cannot be shorter than the path without that edge. If we allow negative weights, we can no longer rely on this. Consider the following graph for instance — the shortest path algorithm will not find the shortest path in this case.
Summary
This article has presented a derivation of Dijkstra’s shortest path algorithm, in the constructionist style of Edsger Dijkstra. It has done so as a birthday salute to the algorithm and the man who invented it.