In my previous blog post I wrote about a groovy client for reading a wordpress blog. Than using this client I send the data to ElasticSearch to be indexed. Of course you cannot do anything with ElasticSearch if you do not read the data by executing queries. So that blog post also talks about executing search queries and doing count queries.
But what if you want to start playing with things like facets? What if we want to use a different analyzer to separate the keywords on a comma? Than you can use curl. No wait there is more. You can also use groovy of course.
That is what I discuss in this blog post, creating and removing indexes. Beware, this is not something you want to do on your production server. Deleting an index makes the index disappear, yes for real, you cannot get it back.
Read on if you want to learn more about groovy and ElasticSearch.
Prequel
Please read my previous post if you want to understand the sample that I am creating. I will not discuss it in this blog post.
Delete an index
Again be careful, usually this is not possible in production. You should disable it.
The ElasticSearchGateway contains the following method to delete an index.
public deleteIndex() {
try {
def response = node.client.admin.indices.prepareDelete(indexValue).execute().get()
if (response.acknowledged) {
println "The index is removed"
} else {
println "The index could not be removed"
}
} catch (Exception e) {
println "The index you want to delete is missing : ${e.message}"
}
}
node is an instance of GNode created in the constructor of my Gateway class. You ask for the client to get access to the ElasticSearch cluster. Than ask for the admin part on which you can call index related queries. In this case we call the prepareDelete method. I put a try-catch around the delete statement. I do not want the script to stop if the index cannot be deleted because it is not there.
Creating the index
Before I show you have to create an index with some advanced stuff going on in there, I want to explain why I needed it. I want to create facets around the keywords and the categories in my blogs. The format of the keywords field is:
Yvonne van der Mey, fotografie, bloemen
I want three terms out of this after analyzing for creating facets. Therefore I want to tokenize based on the comma and I want to strip the spaces from the items. This can be done with a custom analyzer. The custom analyzer refers to a pattern based tokenizer and a trimming filter. In groovy you can create this index, with settings and mappings as shown in the next block.
public createIndex() {
def future = node.client.admin.indices.create {
index = this.indexValue
settings {
number_of_shards = "1"
analysis {
analyzer {
comma {
type = "custome"
tokenizer = "bycomma"
filter = ["nowhite"]
}
}
tokenizer {
bycomma {
type = "pattern"
pattern = ","
}
}
filter {
nowhite {
type = "trim"
}
}
}
}
mapping this.typeValue, {
"${this.typeValue}" {
properties {
keywords {
type = "string"
analyzer = "comma"
}
categories {
type = "string"
analyzer = "comma"
}
}
}
}
}
future.success = { CreateIndexResponse response ->
println "Index is created"
}
future.failure = {
println "ERROR creating index $it"
}
}
With groovy you can use the closure notation to create these items like settings and mappings. This way the method with a string containing the source is called and the closure is transformed into the json structure. The notation looks very similar to the json as provided when using curl.
A nice way to test if your analyzer works is using curl. You can actually call the analyzer with a string to be analyzed.
[~]$ curl -XGET 'localhost:9200/coenradie/_analyze?analyzer=comma&pretty=true' -d 'this ,is a ,test, with a lot of,difference,'
{
"tokens" : [ {
"token" : "this",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 1
}, {
"token" : "is a",
"start_offset" : 6,
"end_offset" : 11,
"type" : "word",
"position" : 2
}, {
"token" : "test",
"start_offset" : 12,
"end_offset" : 16,
"type" : "word",
"position" : 3
}, {
"token" : "with a lot of",
"start_offset" : 17,
"end_offset" : 31,
"type" : "word",
"position" : 4
}, {
"token" : "difference",
"start_offset" : 32,
"end_offset" : 42,
"type" : "word",
"position" : 5
} ]
}
As you can see, the spaces at the end and beginning are removed, but we have multiple words as one token. Exactly like I want.
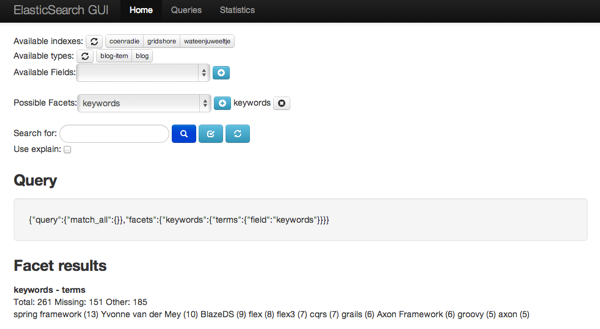
The code also shows we use this analyzer for two fields: keywords and categories. The next screen shows another project I am working on. This project is actually the main project but I needed some content so I created the groovy scripts to find content and send them to ElasticSearch. Check the facets at the bottom of the screen.
I hop you like this addition. My next blog will be about ElasticSearch and writing a plugin using AngularJS.